How we commoditized GPUs for Kubernetes
-
Over the last 4 months I have blogged 4 times about the enablement of GPUs in Kubernetes. Each time I did so, I spent several days building and destroying clusters until it was just right, making the experience as fluid as possible for adventurous readers.
It was not the easiest task as the environments were different (cloud, bare metal), the hardware was different (g2.xlarge have old K20s, p2 instances have K80s, I had 1060GTX at home but on consumer grade Intel NUC…). As a result, I also spent several hours supporting people to set up clusters. Usually with success, but I must admit some environments have been challenging.
Thankfully the team at Canonical in charge of developing the Canonical Distribution of Kubernetes have productized GPU integration and made it so easy to use that it would just be a shame not to talk about it.
And as of course happiness never comes alone, I was lucky enough to be allocated 3 brand new, production grade Pascal P5000 by our nVidia friends. I could have installed these in my playful rig to replace the 1060GTX boards. But this would have showed little gratitude for the exceptional gift I received from nVidia. Instead, I decided to go for a full blown “production grade” bare metal cluster, which will allow me to replicate most of the environments customers and partners have. I chose to go for 3x Dell T630 servers, which can be GPU enabled and are very capable machines. I received them a couple of week ago, and…

Please don’t mind the cables, I don’t have a rack…There we are! Ready for some awesomeness?What it was in the past
If you remember the other posts, the sequence was:
- Deploy a “normal” K8s cluster with Juju;
- Add a CUDA charm and relate it to the right group of Kubernetes workers;
- Connect on each node, and activate privileged containers, and add the experimental-nvidia-gpu tag to the kubelet. Restart kubelet;
- Connect on the API Server, add the experimental-nvidia-gpu tag and restart the API server;
- Test that the drivers were installed OK and made available in k8s with Juju and Kubernetes commands.
Overall, on top of the Kubernetes installation, with all the scripting in the world, no less than 30 to 45min were lost to perform the specific maintenance for GPU enablement.
It is better than having no GPUs, but it is often too much for the operators of the clusters who want an instant solution.How is it now?
I am happy to say that the requests of the community have been heard loud and clear. As of Kubernetes 1.6.1, and the matching GA release of the Canonical Distribution of Kubernetes, the new experience is :
- Deploy a normal K8s cluster with Juju
Yes, you read that correctly. Single command deployment of GPU-enabled Kubernetes Cluster
Since 1.6.1, the charms will now:
- watch for GPU availability every 5min. For clouds like GCE, where GPUs can be added on the fly to instances, this makes sure that no GPU will ever be forgotten;
- If one or more GPUs are detected on a worker, the latest and greatest CUDA drivers will be installed on the node, the kubelet reconfigured and restarted automagically;
- Then the worker will communicate its new state to the master, which will in return also reconfigure the API server and accept GPU workloads;
- In case you have a mixed cluster with some nodes with GPUs and others without, only the right nodes will attempt to install CUDA and accept privileged containers.
You don’t believe me? Fair enough. Watch me…
Requirements
For the following, you’ll need:
- Basic understanding of the Canonical toolbox: Ubuntu, Juju, MAAS…
- Basic understanding of Kubernetes
- A little bit of Helm at the end
and for the files, cloning the repo:
git clone https://github.com/madeden/blogposts cd blogposts/k8s-ethereumPutting it to the test
In the cloud
Deploying in the cloud is trivial. Once Juju is installed and your credentials are added,
juju bootstrap aws/us-east-1 juju deploy src/bundles/k8s-1cpu-3gpu-aws.yaml watch -c juju status --colorNow wait…
Model Controller Cloud/Region Version default aws-us-east-1 aws/us-east-1 2.2-beta2 App Version Status Scale Charm Store Rev OS Notes easyrsa 3.0.1 active 1 easyrsa jujucharms 8 ubuntu etcd 2.3.8 active 1 etcd jujucharms 29 ubuntu flannel 0.7.0 active 2 flannel jujucharms 13 ubuntu kubernetes-master 1.6.1 waiting 1 kubernetes-master jujucharms 17 ubuntu exposed kubernetes-worker-cpu 1.6.1 active 1 kubernetes-worker jujucharms 22 ubuntu exposed kubernetes-worker-gpu maintenance 3 kubernetes-worker jujucharms 22 ubuntu exposed Unit Workload Agent Machine Public address Ports Message easyrsa/0* active idle 0/lxd/0 10.0.201.114 Certificate Authority connected. etcd/0* active idle 0 52.91.177.229 2379/tcp Healthy with 1 known peer kubernetes-master/0* waiting idle 0 52.91.177.229 6443/tcp Waiting for kube-system pods to start flannel/0* active idle 52.91.177.229 Flannel subnet 10.1.4.1/24 kubernetes-worker-cpu/0* active idle 1 34.207.180.182 80/tcp,443/tcp Kubernetes worker running. flannel/1 active idle 34.207.180.182 Flannel subnet 10.1.29.1/24 kubernetes-worker-gpu/0 maintenance executing 2 54.146.144.181 (install) Installing CUDA kubernetes-worker-gpu/1 maintenance executing 3 54.211.83.217 (install) Installing CUDA kubernetes-worker-gpu/2* maintenance executing 4 54.237.248.219 (install) Installing CUDA Machine State DNS Inst id Series AZ Message 0 started 52.91.177.229 i-0d71d98b872d201f5 xenial us-east-1a running 0/lxd/0 started 10.0.201.114 juju-29e858-0-lxd-0 xenial Container started 1 started 34.207.180.182 i-04f2b75f3ab88f842 xenial us-east-1a running 2 started 54.146.144.181 i-0113e8a722778330c xenial us-east-1a running 3 started 54.211.83.217 i-07c8c81f5e4cad6be xenial us-east-1a running 4 started 54.237.248.219 i-00ae437291c88210f xenial us-east-1a running Relation Provides Consumes Type certificates easyrsa etcd regular certificates easyrsa kubernetes-master regular certificates easyrsa kubernetes-worker-cpu regular certificates easyrsa kubernetes-worker-gpu regular cluster etcd etcd peer etcd etcd flannel regular etcd etcd kubernetes-master regular cni flannel kubernetes-master regular cni flannel kubernetes-worker-cpu regular cni flannel kubernetes-worker-gpu regular cni kubernetes-master flannel subordinate kube-dns kubernetes-master kubernetes-worker-cpu regular kube-dns kubernetes-master kubernetes-worker-gpu regular cni kubernetes-worker-cpu flannel subordinate cni kubernetes-worker-gpu flannel subordinateI was able to capture the moment where it is installing CUDA so you can see it… When it’s done:
juju ssh kubernetes-worker-gpu/0 "sudo nvidia-smi" Tue Apr 18 08:50:23 2017 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 375.51 Driver Version: 375.51 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla K80 Off | 0000:00:1E.0 Off | 0 | | N/A 52C P0 67W / 149W | 0MiB / 11439MiB | 98% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ Connection to 54.146.144.181 closed.That’s it, you can see the K80 from the p2.xlarge instance. I didn’t do anything about it, it was completely automated. This is Kubernetes on GPU steroids.
The important option in the bundle file we deployed is:
options: "allow-privileged": "true"If you want to prevent privileged containers until absolutely necessary, you can use the tag “auto”, which will only activate them if GPUs are detected.
On Bare Metal
Obviously there is a little more to do on Bare Metal, and I will refer you to my previous posts to understand how to set MAAS up & running. This assumes it is already working.
Adding the T630 to MAAS is a breeze. If you don’t change the default iDRAC username password (root/calvin), the only thing you have to do it connect them to a network (a specific VLAN for management is preferred of course), set the IP address, and add to MAAS with an IPMI Power type.
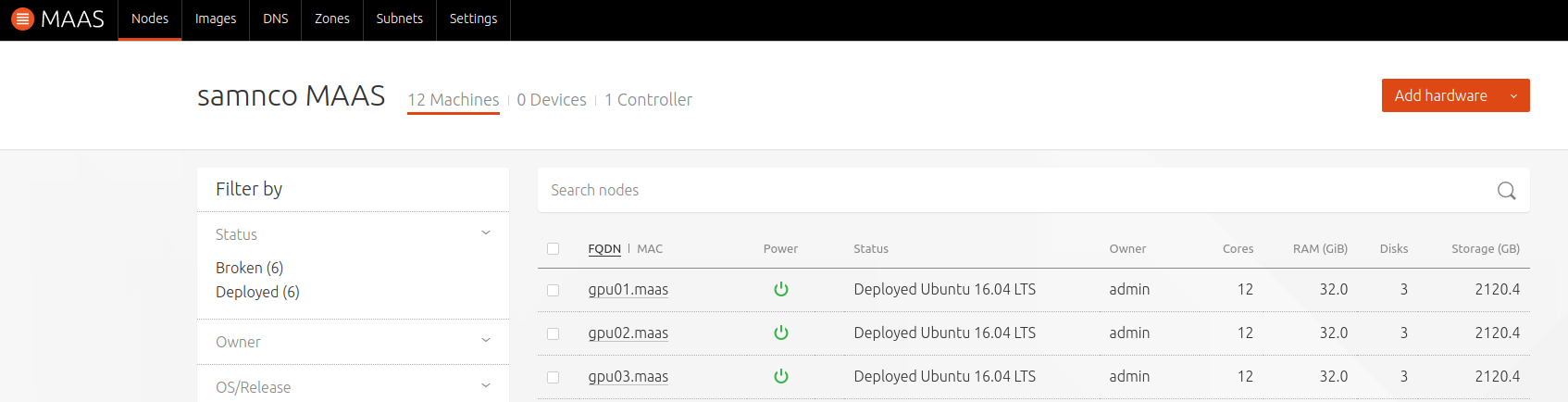
Adding the nodes into MAASThen commission the nodes as you would with any other. This time, you won’t need to press the power button like I had to with the NUC cluster: MAAS will trigger via the IPMI card directly, request a PXE boot, and register the node, all fully automagically. Once that is done, tag them “gpu” to make sure to recognize them.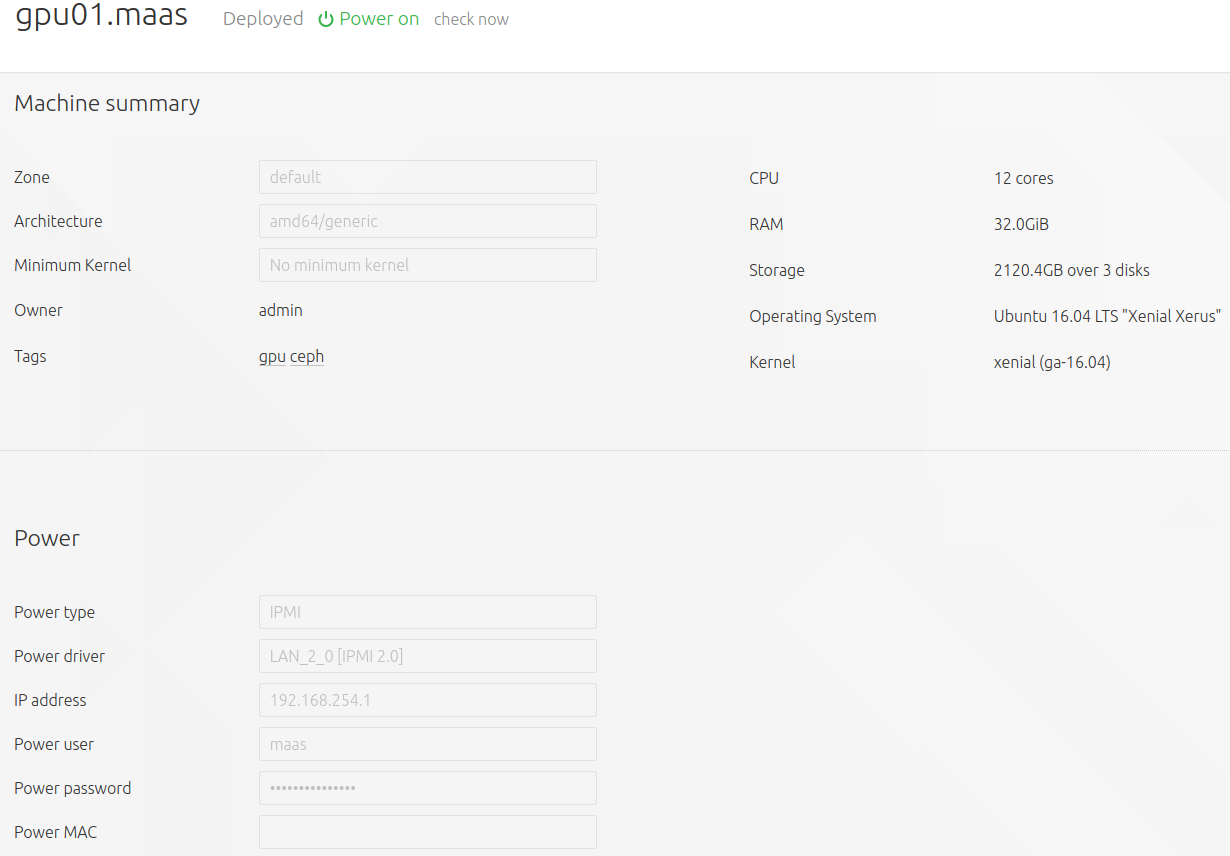
Details about the T630 in MAASThen
juju bootstrap maas juju deploy src/bundles/k8s-1cpu-3gpu.yaml watch -c juju status --colorWait for a few minutes… You will see at some point that the charm is now installing CUDA drivers. At the end,
Model Controller Cloud/Region Version default k8s maas 2.1.2.1 App Version Status Scale Charm Store Rev OS Notes easyrsa 3.0.1 active 1 easyrsa jujucharms 8 ubuntu etcd 2.3.8 active 1 etcd jujucharms 29 ubuntu flannel 0.7.0 active 5 flannel jujucharms 13 ubuntu kubernetes-master 1.6.1 active 1 kubernetes-master jujucharms 17 ubuntu exposed kubernetes-worker-cpu 1.6.1 active 1 kubernetes-worker jujucharms 22 ubuntu exposed kubernetes-worker-gpu 1.6.1 active 3 kubernetes-worker jujucharms 22 ubuntu exposed Unit Workload Agent Machine Public address Ports Message easyrsa/0* active idle 0/lxd/0 172.16.0.8 Certificate Authority connected. etcd/0* active idle 0 172.16.0.4 2379/tcp Healthy with 1 known peer kubernetes-master/0* active idle 0 172.16.0.4 6443/tcp Kubernetes master running. flannel/1 active idle 172.16.0.4 Flannel subnet 10.1.9.1/24 kubernetes-worker-cpu/0* active idle 1 172.16.0.5 80/tcp,443/tcp Kubernetes worker running. flannel/0* active idle 172.16.0.5 Flannel subnet 10.1.20.1/24 kubernetes-worker-gpu/0 active idle 2 172.16.0.6 80/tcp,443/tcp Kubernetes worker running. flannel/2 active idle 172.16.0.6 Flannel subnet 10.1.91.1/24 kubernetes-worker-gpu/1 active idle 3 172.16.0.7 80/tcp,443/tcp Kubernetes worker running. flannel/4 active idle 172.16.0.7 Flannel subnet 10.1.19.1/24 kubernetes-worker-gpu/2* active idle 4 172.16.0.3 80/tcp,443/tcp Kubernetes worker running. flannel/3 active idle 172.16.0.3 Flannel subnet 10.1.15.1/24 Machine State DNS Inst id Series AZ 0 started 172.16.0.4 br68gs xenial default 0/lxd/0 started 172.16.0.8 juju-5a80fa-0-lxd-0 xenial 1 started 172.16.0.5 qkrh4t xenial default 2 started 172.16.0.6 4y74eg xenial default 3 started 172.16.0.7 w3pgw7 xenial default 4 started 172.16.0.3 se8wy7 xenial default Relation Provides Consumes Type certificates easyrsa etcd regular certificates easyrsa kubernetes-master regular certificates easyrsa kubernetes-worker-cpu regular certificates easyrsa kubernetes-worker-gpu regular cluster etcd etcd peer etcd etcd flannel regular etcd etcd kubernetes-master regular cni flannel kubernetes-master regular cni flannel kubernetes-worker-cpu regular cni flannel kubernetes-worker-gpu regular cni kubernetes-master flannel subordinate kube-dns kubernetes-master kubernetes-worker-cpu regular kube-dns kubernetes-master kubernetes-worker-gpu regular cni kubernetes-worker-cpu flannel subordinate cni kubernetes-worker-gpu flannel subordinateAnd now:
juju ssh kubernetes-worker-gpu/0 "sudo nvidia-smi" Tue Apr 18 06:08:35 2017 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 375.51 Driver Version: 375.51 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 106... Off | 0000:04:00.0 Off | N/A | | 28% 37C P0 28W / 120W | 0MiB / 6072MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Quadro P5000 Off | 0000:83:00.0 Off | Off | | 0% 43C P0 39W / 180W | 0MiB / 16273MiB | 2% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+That’s it, my 2 cards are in there: 1060GTX and P5000. Again, no user interaction. How awesome is this?
Note that the interesting aspects are not only that it automated the GPU enablement, but also that the bundle files (the yaml content) are essentially the same, but for the machine constraints we set.
Having some fun with GPUs
If you follow me you know I’ve been playing with Tensorflow, so that would be a use case, but I actually wanted to get some raw fun with them! One of my readers mentioned bitcoin mining once, so I decided to go for it.
I made a quick and dirty Helm Chart for an Ethereum Miner, along with a simple rig monitoring system called ethmon.
This chart will let you configure how many nodes, and how many GPU per node you want to use. Then you can also tweak the miner. For now, it only works in ETH only mode. Don’t forget to create a values.yaml file to
- add your own wallet (if you keep the default you’ll actually pay me, which is fine
 but not necessarily your purpose),
but not necessarily your purpose), - update the ingress xip.io endpoint to match the public IP of one of your workers or use your own DNS
- Adjust the number of workers and GPUs per node
then
cd ~ git clone https://github.com/madeden/charts.git cd charts helm init helm install claymore --name claymore --values /path/to/yourvalues.yamlBy default, you’ll get the 3 worker nodes, with 2 GPUs (this is to work on my rig at home)
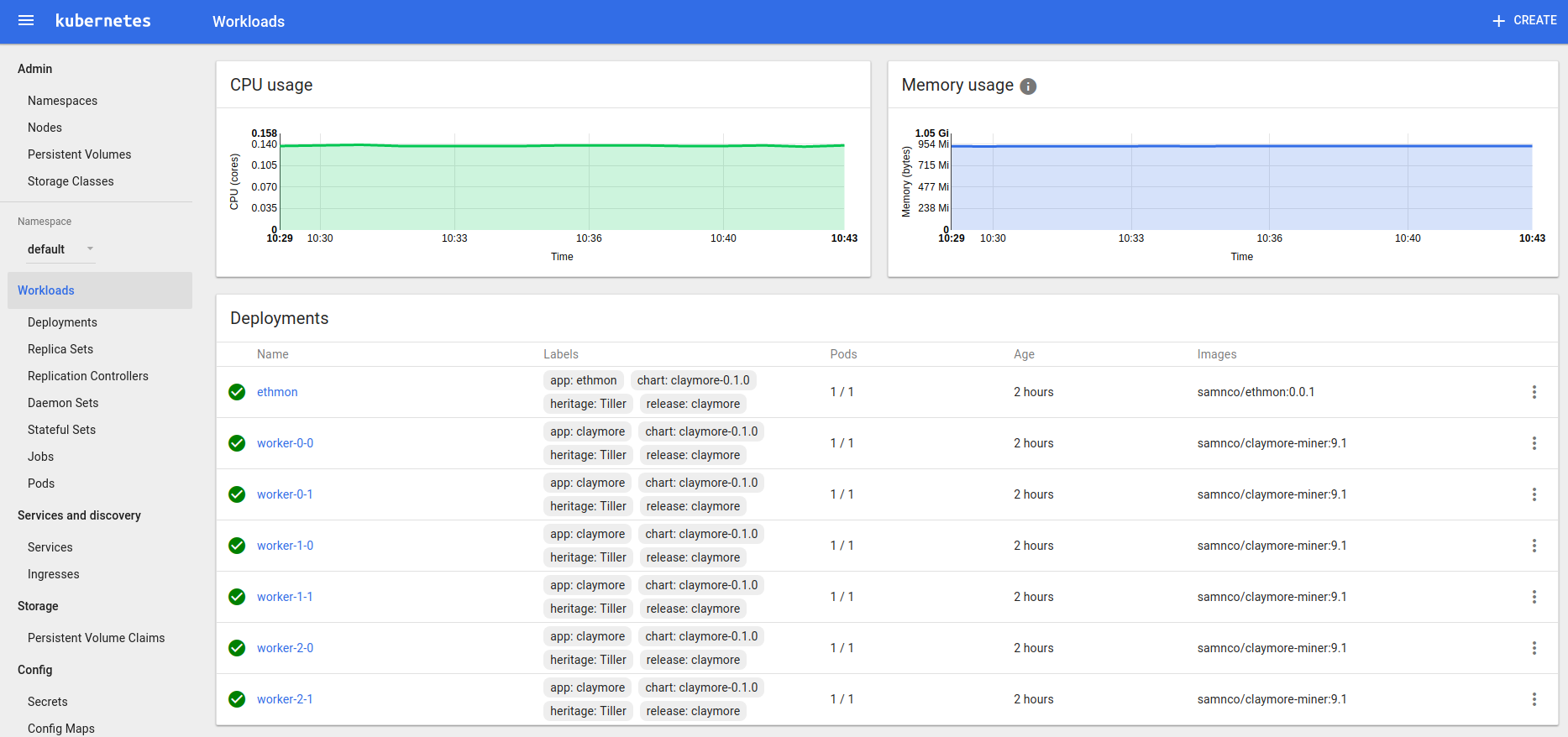
KubeUI with the miners deployed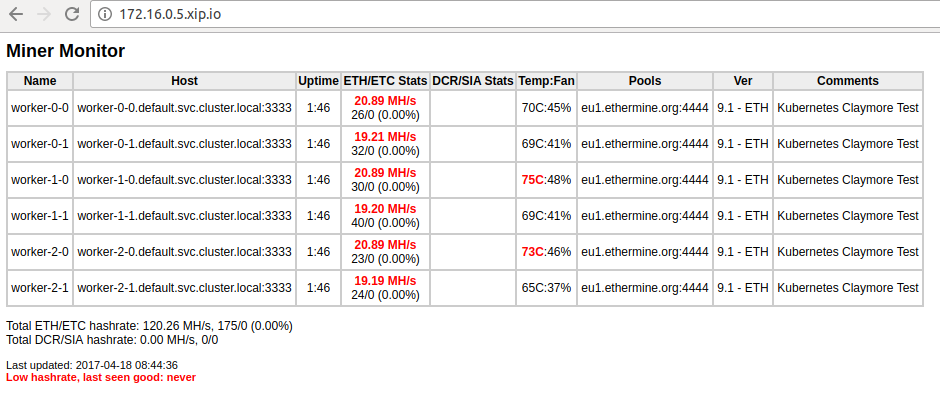
Monitoring interface (ethmon)You can also track it here with nice graphs.What did I learn from it? Well,
- I really need to work on my tuning per card here! The P5000 and the 1060GTX have the same performances, and they also are the same as my Quadro M4000. This is not right (or there is a cap somewhere). But I’m a newbie, I’ll get better.
- It’s probably not worth it money wise. This would make me less than $100/month with this cluster, less than my electricity bill to run it.
- There is a LOT of room for Monero mining on the CPU! I run at less than a core for the 6 workers.
- I’ll probably update it to run less workers, but with all the GPUs allocated to them.
- But it was very fun to make. And now apparently I need to do “monero”, which is supposedly ASIC resistent and should be more profitable. Stay tuned

Conclusion
3 months ago, I recognize running Kubernetes with GPUs wasn’t a trivial job. It was possible, but you needed to really want it.
Today, if you are looking for CUDA workloads, I challenge you to find anything easier than the Canonical Distribution of Kubernetes to run that, on Bare Metal or in the cloud. It is literally so trivial to make it work that it’s boring. Exactly what you want from infrastructure.
GPUs are the new normal. Get used to it.
So, let me know of your use cases, and I will put this cluster to work on something a little more useful for mankind than a couple of ETH!
I am always happy to do some skunk work, and if you combine GPUs and Kubernetes, you’ll just be targeting my 2 favorite things in the compute world. Shoot me a message @SaMnCo_23!
https://insights.ubuntu.com/2017/04/19/how-we-commoditized-gpus-for-kubernetes/
© Lightnetics 2024